 ATMARK хостинговая компания
ATMARK хостинговая компания
top – одна из наиболее распространённых и удобных в своей линейке утилит, предназначенная для мониторинга состояния сервера.
Программа top динамически выводит в режиме реального времени информации о работающей системе, т.е. о фактической активности процессов. По умолчанию она выдает задачи, наиболее загружающие процессор сервера, и обновляет список каждые две секунды.
Управляющие клавиши:
t – Включение и выключение выдачи на экран суммарных данных.
m – Включение и выключение выдачи на экран информации об использовании памяти.
1 – По умолчанию выводятся данные для одного ЦП (ядра). Этот переключатель позволяет увидеть данные по каждому ЦП.
f – Вход в меню интерактивного конфигурирования данных, выдаваемых на экран командой top. Полезна для настройки команды top для выполнения специфической задачи.
o – Позволяет вам интерактивно задавать порядок строк, выдаваемой командой top.
r – Изменение приоритета процессов с помощью команды renice.
k – Удаление процесса с помощью команды kill. Программа запрашивает у вас код процесса и сигнал, который будет ему послан.
z – Переключение между цветным / монохромным вариантом выдачи изображения.
q – Выйти из программы
[Пробел] – Немедленно обновить содержимое экрана.
n – Изменить число отображаемых процессов. Вам предлагается ввести число.
u – Сортировать по имени пользователя.
M – Сортировать по объёму используемой памяти.
P – Сортировать по загрузке процессора.
A – Сортировка строк по максимальному потреблению различных системных ресурсов. Полезна для быстрой идентификации задач, для которых в системе не хватает ресурсов.
W – Создание персональных настроек в файле .toprc
По имени этой утилиты позже были названы и другие аналогичные продукты – atop, htop, iftop, iotop и многие другие. Цель у всех одна – отобразить текущую нагрузку на весь сервер или отдельные его подсистемы.
Утилита top входит в пакет программ procps. Кроме top в него так же входят такие утилиты как free, kill, pgrep, pkill, pmap, ps, skill, snice, sysctl, tload, uptime, vmstat, w и watch. Данные для отображения утилиты берут в основном из каталога /proc.
Перейдём к рассмотрению выводимых данных.
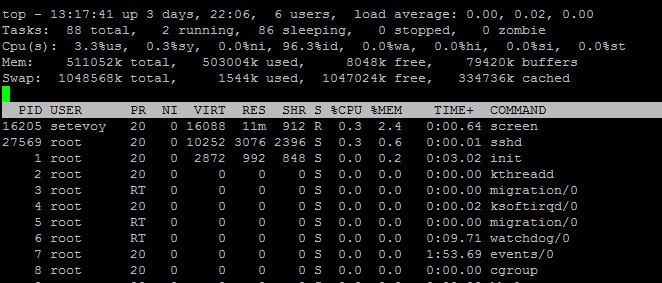
Самая важная и нужна информация – это первая строка, отображающая Load Avarage (далее – LA):

Данные выводятся в трёх временных промежутка – 1 минута назад, 5 минут и 15 минут.
Как узнать какое значение Load Avarage является нормальным? Тут всё зависит от количества ядер.
Для примера – сервер с CPU у которого 1 ядро:
Показатель LA меньше 1 – самое хорошее значение, нагрузки практически нет;
1-3 – нагрузка в пределах нормы, сервер достаточно нагружен работой – но эта нагрузка в пределах нормы;
3-10 – это уже серьёзная нагрузка, следует обратить внимание на процессы, HDD и прочие параметры;
Нагрузка более 10 – серьёзные проблемы, заметно “торможение” сервера при обработке запросов;
20 и более – очень серьёзные проблемы, доступ к серверу серьёзно затруднён.
Для серверов, у которых количество ядре в процессоре более 1-го – эти значения необходимо увеличить на кол-во ядер в системе.
Так же полезная информация выводится в начале строки с Load Avarages:

Сначала отображается текущее системное время процессора
Далее отображается информация о текущих процессах:

running — процессы, выполняющиеся в данный момент;
sleeping — “спящие” процессы, процесс находится в состоянии ожидания запроса или в готовности;
zombie — “зомби”-процесс, дочерний процесс, завершивший свой выполнение, но но ещё присутствующий в списке процессов операционной системы, чтобы дать родительскому процессу считать код завершения.
Далее выводится информация об использовании процессора:

us% — процент времени, потраченного на выполнение процессов пользователей, для которых не задан приоритет;
sy% — это процент времени, потраченного на выполнение процессов ядра;
ni% — процент времени, потраченного на выполнение процессов с заданных приоритетом;
wa% — это процент времени, потраченного на выполнение операций IO (вводавывода), то есть дисковых операций;
hi% — это процент времени, потраченный на обработку аппаратных прерываний;
si% — процент времени, потраченного на обработку программных прерываний;
st% — процент времени, «украденного» у виртуальной машины гипервизором для каких-либо других задач, к примеру, запуска другой виртуальной машины.
Далее размещается информация о использовании оперативной памяти.

total — это суммарный объем оперативной памяти сервера;
used — это объем использованной памяти;
free — объем свободной памяти;
buffers — объем буфера;
cached — объем кеша операций вводавывода.
Это же касается SWAP-раздела.
Далее – выводится информация о текущих процессах:

PID — числовой идентификатор процесса;
USER — это пользователь, который инициировал запуск процесса;
PR — динамический приоритет процесса;
NI — статический приоритет процесса;
VIRT — объем использования виртуальной памяти (включая весь код, библиотеки и т.д.);
RES — объем использования реальной оперативной памяти;
SHR — объем использованной shared-памяти (эта память может использоваться и другими приложениями);
S — статус процесса (выполняется, ожидает, остановлен и т.д.);
R (running) – выполняется;
S (sleeping) – “спящий” процесс;
Z (zombie) – процесс-“зомби”.
%CPU — процент использования процессорного времен;
%MEM — процент использования реальной оперативной памяти;
TIME — время работы процесса с момента запуска;
COMMAND — имя процесса.